
Bash 快捷键 命令执行顺序,详解通配符

Bash 快捷键 命令执行顺序,详解通配符
Wang Zihao目录
Bash 常用快捷键
Ctrl + A 把光标移动到命令行开头
Ctrl + E 把光标移动到命令行尾
Ctrl + D 退出当前终端 ( 正常的退出 )
Ctrl + C 强制终止当前命令 ( 非正常的退出 )
Ctrl + L 清屏
Ctrl + U 删除或剪切光标之前的命令
Ctrl + K 删除或剪切光标之后的命令
Ctrl + Y 粘贴 Ctrl + U 或 Ctrl + K 剪切的内容
Ctrl + R 在历史命令中搜索
Ctrl + Z 暂停,并放入后台
Ctrl + S 暂停屏幕输出
Ctrl + Q 恢复屏幕输出
输入输出重定向
Bash 的标准输入输出
设备 设备文件名 文件描述符 类型
键盘 /dev/stdin 0 标准输入
显示器 /dev/stdout 1 标准输出
显示器 /dev/stderr 2 标准错误输出
<< 用法
快速生成文件
===>>
1 | [root@localhost ~]# cat > test1.txt << EOF |
当键盘输入 EOF 的时候,就会结束,就是 结束符 ~!!
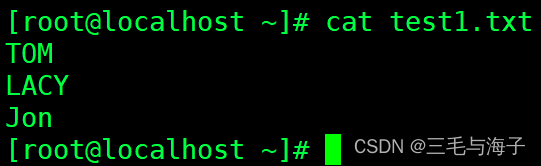
这样 test1.txt 就生成了 ~!!!
输出重定向
| 类型 | 符号 | 作用 |
| 标准输出重定向 | 命令 > 文件 | 以覆盖的方式,把命令的正确输出,输出到指定的文件或设备当中 |
| 命令 >> 文件 | 以追加的方式,把命令的正确输出,输出到指定的文件或设备当中 | |
| 标准错误输出重定向 | 错误命令 2> 文件 | 以覆盖的方式,把命令的错误输出,输出到指定的文件或设备当中 |
| 错误命令 2>> 文件 | 以追加的方式,把命令的错误输出,输出到指定的文件或设备当中 | |
| 正确输出和错误输出同时保存 | 命令 > 文件 2>&1 | 以覆盖的方式,把正确输出和错误输出,都保存到同一个文件当中 |
| 命令 >> 文件 2>&1 | 以追加的方式,把正确输出和错误输出,都保存到同一个文件当中 | |
| 命令 &> 文件 | 以覆盖的方式,把正确输出和错误输出,都保存到同一个文件当中 | |
| 命令 &>> 文件 | 以追加的方式,把正确输出和错误输出,都保存到同一个文件当中 | |
| 命令 >> 文件1 2>>文件 2 | 把正确的输出追加到文件1中,把错误的输出追加到文件2中 |
命令执行顺序
; 分号
– 命令的顺序执行
===>>>
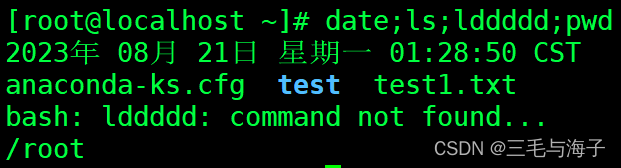
不管前面的命令是否执行成功,都会挨个执行一遍,即使中间有的命令没能执行成功,也会接着
执行后面的命令。
&&
– 前面命令执行不成功,后面的命令不执行
===>>>

显然,前面 lddd 命令执行不成功,后面的 pwd 也就不执行了 ~!!
||
– 前面的命令执行成功,后面的命令就不执行; 前面的命令执行不成功,后面的命令才执行
===>>>
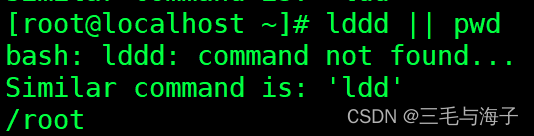
前面命令执行不成功,则执行后面命令

前面命令执行成功了,后面命令就不执行了 ~!!!
拓展 : 面试题
如果用户 hadoop 不存在则创建
===>>>
首先,我们如何判断用户是否存在呢 ??
===>>>
那就是 id 命令了, id 用户名

那我们就可以根据 id 用户名 是否执行成功来判断 该用户是否存在,
即利用命令的返回值来判断,并且,我们又不需要这个命令执行的结果,只要这个命令是否
执行成功的返回值。
===>>>
1 | [root@localhost ~]# id hadoop &> /dev/null |
这就是 我们将命令执行,执行完后把结果扔到 回收站 ( 我们不要执行结果 )
完整执行为
===>>>
1 | [root@localhost ~]# id hadoop &> /dev/null || userhad hadoop |
我们就用到了 || 符, 即前面的命令要是执行成功了,那就不需要再创建该用户;
要是 || 符 前面的命令没执行成功,那就说明没有该用户,那就执行 || 后面的命令,创建用户
通配符
传统通配符
? 匹配一个任意字符
‘ * ‘ 匹配0个或任意多个任意字符,也就是可以匹配任意内容
[ ] 匹配 [ ] 中任意一个字符
[ - ] 匹配 [ ] 中任意一个字符, - 代表一个范围,从哪儿到哪儿
[ ^ ] 逻辑非,表示匹配不是中括号内的一个字符
示例 :
创建一系列文件,提供素材
1 | [root@localhost test]# touch test.txt |
?
===>>>

没有 test.txt 和 test10 - test20.txt
‘ * ‘
===>>>

所有 test.txt 的文件都列出了,包括 test.txt 理解 0个或多个 任意字符
[ ]
===>>>

[ ] 中 任意 一个字符
[ - ]
===>>>

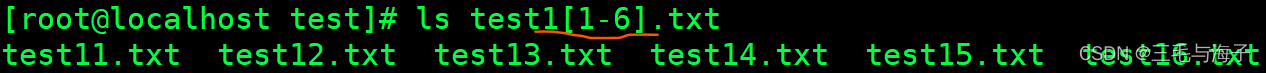
注意列出 test11 到 test16 的文件时,那就得 往外提一个 1 出去,因为 [ ] 里只能匹配一个字符
列出以小写字母开头,结尾时 .sh 的文件
===>>>
1 | [root@localhost test]# ls [a-z]*.txt |
[ ^ ]
===>>>

不想要 test1 test3 test5 文件,所以就取反; 注意列出的 也并没有 test10-test20 .txt 的文件哦
常用字符
[ [:class:] ] : 匹配一个属于指定字符类中的字符
[:class:] 表示一种字符类,比如: 数字,大小写字母等
常用字符类 :
[:alnum:] : 匹配任意一个字母或数字,传统写法 : a-zA-Z0-9
[:alpha:] : 匹配任意一个字母, 传统写法 : a-zA-Z
[:digit:] : 匹配任意一个数字, 传统写法 : 0-9
[:lower:] : 匹配任意一个小写字母 传统写法 : a-z
[:upper:] : 匹配任意一个大写字母 传统写法 : A-Z
注 : 在使用专属字符集的时候,字符集之外还需要 [ ] 来包含,否则不能生效 ~!!
如果使用上述格式的话,那对它的取反就是 在两个括号的中间进行取反
如 : [^[ : alnum:]] [^[:digit:]] [^[:lower:]] 等等
列出 以小写字母开头,.txt 结尾的文件
===>>>
1 | [root@localhost test]# ls [[:lower:]]*.txt |
强调 : { } 生成序列
{ } 生成序列
touch file{1..9}.txt # 当前路径生成 file1.txt-file9.txt 。 { a..f } 代表 a-f
不连续的使用 , 分隔,比如 file{1,3,5}.txt 那就是 file1.txt file3.txt file5.txt
利用 { } 备份
[root@localhost test]# cp test1.txt{,.bak} # 将test1.txt 复制一份叫 test1.txt.bak
[root@localhost test]# cp test{2,22}.txt # 复制 test2.txt 为 test22.txt
示例 :
列出 /etc/ 目录中不是以字母 a 到 n 开头的,并且以 .conf 结尾的文件
===>>>
1 | [root@localhost test]# ls /etc/[^a-n]*.conf |
列出 /bin/ 下以 c 或 k 开头的文件
===>>>
1 | [root@localhost test]# ls /bin/[ck]* |







