训练
按照昨天的思路改了下损失函数和优化器,效果如下图:
1
| nnUNetTrainerAdan__nnUNetPlans__3d_fullres
|

1
| nnUNetTrainerDiceLoss__nnUNetPlans__3d_fullres
|
没法评价,给我气笑了。
昨天云龙给了我个多尺度特征提取模块,今天想办法加进去看看效果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| import torch.nn as nn
class MBTFE(nn.Module):
def __init__(self, in_channels, out_channels):
super(MBTFE, self).__init__()
# 多尺度特征提取
# 1×1×1层
self.conv1 = nn.Conv3d(in_channels, out_channels, kernel_size=1)
self.bn1 = nn.BatchNorm3d(out_channels)
self.prelu1 = nn.PReLU(out_channels)
# 3×3×3层
self.conv3 = nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm3d(out_channels)
self.prelu3 = nn.PReLU(out_channels)
# 5×5×5层
self.conv5_1 = nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1)
self.bn5_1 = nn.BatchNorm3d(out_channels)
self.prelu5_1 = nn.PReLU(out_channels)
self.conv5_2 = nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn5_2 = nn.BatchNorm3d(out_channels)
self.prelu5_2 = nn.PReLU(out_channels)
# 7×7×7层
self.conv7_1 = nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1)
self.bn7_1 = nn.BatchNorm3d(out_channels)
self.prelu7_1 = nn.PReLU(out_channels)
self.conv7_2 = nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn7_2 = nn.BatchNorm3d(out_channels)
self.prelu7_2 = nn.PReLU(out_channels)
self.conv7_3 = nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn7_3 = nn.BatchNorm3d(out_channels)
self.prelu7_3 = nn.PReLU(out_channels)
# 相关性计算
self.avg_pool = nn.AdaptiveAvgPool3d(1)
self.fc1 = nn.Linear(out_channels, int(out_channels / 2))
self.fc2 = nn.Linear(int(out_channels / 2), out_channels)
# 特征选取
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
# 多尺度特征提取
out1 = self.prelu1(self.bn1(self.conv1(x)))
out2 = self.prelu3(self.bn3(self.conv3(x)))
out3 = self.prelu5_1(self.bn5_1(self.conv5_1(x)))
out3 = self.prelu5_2(self.bn5_2(self.conv5_2(out3)))
out4 = self.prelu7_1(self.bn7_1(self.conv7_1(x)))
out4 = self.prelu7_2(self.bn7_2(self.conv7_2(out4)))
out4 = self.prelu7_3(self.bn7_3(self.conv7_3(out4)))
out = out1 + out2 + out3 + out4
# 相关性计算
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.fc2(out)
weight_map = self.softmax(out)
# 特征选取
out1 = weight_map[:, 0].unsqueeze(1) * out1
out2 = weight_map[:, 1].unsqueeze(1) * out2
out3 = weight_map[:, 2].unsqueeze(1) * out3
out4 = weight_map[:, 3].unsqueeze(1) * out4
out = out1 + out2 + out3 + out4
return out
|
直接加肯定是不行的,改改加进去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| class MBTFE(nn.Module):
def __init__(self, in_channels, out_channels):
super(MBTFE, self).__init__()
# 多尺度特征提取
# 1×1×1层
self.conv1 = nn.Conv3d(in_channels, out_channels, kernel_size=1)
self.bn1 = nn.BatchNorm3d(out_channels)
self.prelu1 = nn.PReLU(out_channels)
# 3×3×3层
self.conv3 = nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm3d(out_channels)
self.prelu3 = nn.PReLU(out_channels)
# 5×5×5层
self.conv5_1 = nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1)
self.bn5_1 = nn.BatchNorm3d(out_channels)
self.prelu5_1 = nn.PReLU(out_channels)
self.conv5_2 = nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn5_2 = nn.BatchNorm3d(out_channels)
self.prelu5_2 = nn.PReLU(out_channels)
# 7×7×7层
self.conv7_1 = nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1)
self.bn7_1 = nn.BatchNorm3d(out_channels)
self.prelu7_1 = nn.PReLU(out_channels)
self.conv7_2 = nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn7_2 = nn.BatchNorm3d(out_channels)
self.prelu7_2 = nn.PReLU(out_channels)
self.conv7_3 = nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn7_3 = nn.BatchNorm3d(out_channels)
self.prelu7_3 = nn.PReLU(out_channels)
# 相关性计算
self.avg_pool = nn.AdaptiveAvgPool3d(1)
self.fc1 = nn.Linear(out_channels, out_channels // 2)
self.fc2 = nn.Linear(out_channels // 2, 4) # 输出4个权重,对应4个分支
# 特征选取
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
# 多尺度特征提取
out1 = self.prelu1(self.bn1(self.conv1(x)))
out2 = self.prelu3(self.bn3(self.conv3(x)))
out3 = self.prelu5_2(self.bn5_2(self.conv5_2(self.prelu5_1(self.bn5_1(self.conv5_1(x))))))
out4 = self.prelu7_3(self.bn7_3(self.conv7_3(self.prelu7_2(self.bn7_2(self.conv7_2(self.prelu7_1(self.bn7_1(self.conv7_1(x)))))))))
# 相关性计算
pool = self.avg_pool(out1 + out2 + out3 + out4)
flat = torch.flatten(pool, 1)
weight = self.fc2(self.fc1(flat))
weight_map = self.softmax(weight)
# 特征选取
out1 = weight_map[:, 0].view(-1, 1, 1, 1, 1) * out1
out2 = weight_map[:, 1].view(-1, 1, 1, 1, 1) * out2
out3 = weight_map[:, 2].view(-1, 1, 1, 1, 1) * out3
out4 = weight_map[:, 3].view(-1, 1, 1, 1, 1) * out4
out = out1 + out2 + out3 + out4
return out
|
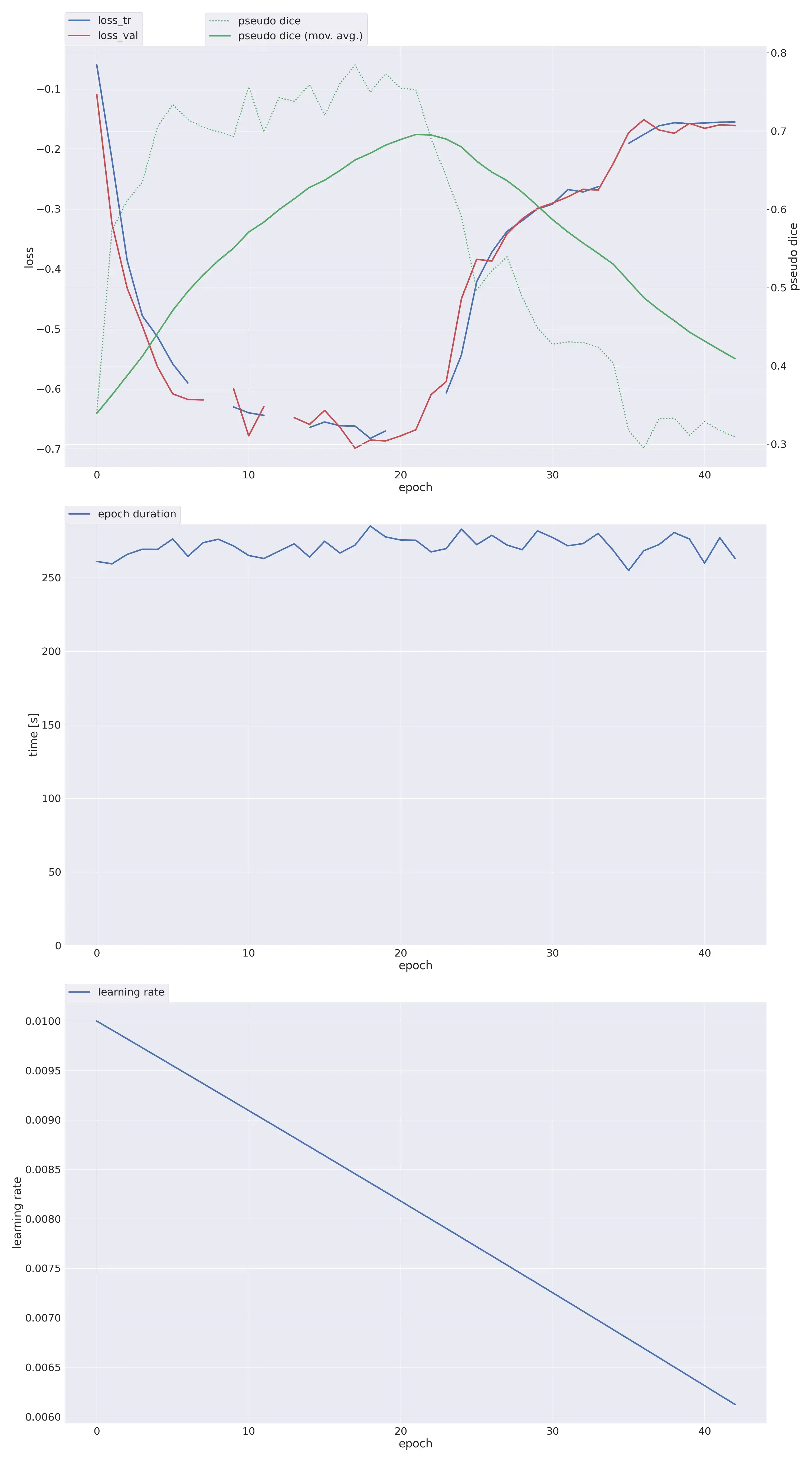
能跑了:
我加了三层,导致参数量膨胀得有点厉害,显存占用直接飙升了10G。还好买的22G显存的卡。
在 PlainConvEncoder 类中,MBTFE 和 EAB 模块的具体数据流如下:
数据流概述
每个阶段的卷积块(stages):
- 输入数据先经过每个阶段的卷积块(
stages)。
- 每个阶段的输出特征图接着进入对应的 MBTFE 模块。
MBTFE 模块:
- MBTFE 模块处理每个阶段的输出特征图,提取多尺度的特征。
- MBTFE 模块的输出特征图返回给
PlainConvEncoder 的 forward 方法,并存储在 ret 列表中。
EAB 模块:
- EAB 模块在前三层特征图上进行特征融合和聚合。
- 在
forward 方法中,EAB 模块处理 ret 列表中的前三个特征图,进行注意力机制、特征融合和上采样。
具体数据流详细说明
1. 每个阶段的卷积块(stages)
1
2
3
4
| for i, s in enumerate(self.stages):
x = s(x)
x = self.mbtfe_modules[i](x)
ret.append(x)
|
- 输入数据
x 依次经过每个阶段的卷积块(self.stages),生成中间特征图。
- 每个阶段的输出特征图
x 接着进入对应的 MBTFE 模块(self.mbtfe_modules[i]),进行多尺度特征提取。
- MBTFE 模块的输出特征图存储在
ret 列表中。
2. MBTFE 模块的输出去向
MBTFE 模块的输出特征图直接存储在 ret 列表中,并在 forward 方法后续处理中使用。
3. EAB 模块处理前三层特征图
1
2
3
4
5
6
7
8
9
10
11
|
m1 = self.mattn(ret[0])
m2 = self.mattn(ret[1])
m3 = self.mattn(ret[2])
m1m2 = torch.cat([self.mdcat1(m1), m2], dim=1)
m_feature = torch.cat([self.mdcat2(m1m2), m3], dim=1)
ret[0] = self.gate1(self.mupcat1(m_feature), ret[0])
ret[1] = self.gate2(self.mupcat2(m_feature), ret[1])
ret[2] = self.gate3(self.mupcat3(m_feature), ret[2])
|
- EAB 模块处理
ret 列表中的前三个特征图。
- 通过
self.mattn 进行注意力机制处理,得到注意力特征图 m1, m2, m3。
- 将
m1 和 m2 拼接,并通过 self.mdcat1 模块处理。
- 将处理后的特征图与
m3 拼接,并通过 self.mdcat2 模块处理,得到融合后的特征图 m_feature。
- 使用转置卷积(
self.mupcat1, self.mupcat2, self.mupcat3)对融合后的特征图进行上采样。
- 使用门控机制(
self.gate1, self.gate2, self.gate3)对上采样后的特征图与原始特征图进行融合,更新 ret 列表中的特征图。
最后两层的处理
最后两层的特征图同样经过 MBTFE 模块处理,但不经过 EAB 模块的特征融合和上采样处理。
总结
MBTFE 数据流:
- 每个阶段的卷积块输出特征图后,输入到对应的 MBTFE 模块。
- MBTFE 模块提取多尺度特征,并将输出特征图存储在
ret 列表中。
EAB 数据流:
- EAB 模块处理
ret 列表中的前三个特征图,进行注意力机制、特征融合和上采样。
- 更新后的特征图存储在
ret 列表中。
通过这种方式,MBTFE 和 EAB 模块协同工作,提升特征提取和融合的能力。
在这个网络结构中,数据流向如下:
- 第一层的输出经过卷积编码器的第二层、MBTFE模块和EAB模块。
- 前三层的输出(即卷积编码器的第一、第二和第三层的输出)都会经过对应的MBTFE模块和EAB模块。
- 后两层的输出(即卷积编码器的第四和第五层的输出)只会经过对应的MBTFE模块。
MBTFE模块的输出将会继续传递给网络的后续部分进行处理。在这个网络结构中,MBTFE模块的输出通常会用于生成更高级的特征表示,或者被传递给其他模块进行后续的任务处理,比如解码器部分用于生成分割结果。因此,MBTFE模块的输出在网络中通常扮演着特征提取和传递的重要角色。.
在 PlainConvEncoder 类中,MBTFE 和 EAB 模块的输出如何流动至下一层编码器的详细说明如下:
MBTFE 数据流
每个阶段的卷积块(stages):
- 输入数据首先经过每个阶段的卷积块(
self.stages)。
- 每个阶段的输出特征图接着进入对应的 MBTFE 模块。
MBTFE 模块:
- MBTFE 模块处理每个阶段的输出特征图,提取多尺度的特征。
- MBTFE 模块的输出特征图存储在
ret 列表中。
EAB 数据流
中间注意力机制:
- 在
forward 方法中,EAB 模块处理 ret 列表中的前三个特征图,进行注意力机制、特征融合和上采样。
- 使用
Spartial_Attention3d 模块对 ret 列表中的每个特征图进行注意力处理,得到注意力特征图。
特征融合和上采样:
- 将第一个阶段的特征图(
m1)通过 mdcat1 模块处理后,与第二个阶段的特征图(m2)进行拼接(使用 torch.cat)。
- 将拼接后的特征图通过
mdcat2 模块处理后,与第三个阶段的特征图(m3)进行拼接。
- 使用转置卷积(
mupcat1, mupcat2, mupcat3)对融合后的特征图进行上采样。
- 使用门控机制(
gate1, gate2, gate3)对上采样后的特征图与原始特征图进行融合,更新 ret 列表中的特征图。
数据流详细说明
1. 每个阶段的卷积块(stages)
1
2
3
4
| for i, s in enumerate(self.stages):
x = s(x)
x = self.mbtfe_modules[i](x)
ret.append(x)
|
- 输入数据
x 依次经过每个阶段的卷积块(self.stages),生成中间特征图。
- 每个阶段的输出特征图
x 接着进入对应的 MBTFE 模块(self.mbtfe_modules[i]),进行多尺度特征提取。
- MBTFE 模块的输出特征图存储在
ret 列表中。
2. EAB 模块处理前三层特征图
1
2
3
4
5
6
7
8
9
10
11
|
m1 = self.mattn(ret[0])
m2 = self.mattn(ret[1])
m3 = self.mattn(ret[2])
m1m2 = torch.cat([self.mdcat1(m1), m2], dim=1)
m_feature = torch.cat([self.mdcat2(m1m2), m3], dim=1)
ret[0] = self.gate1(self.mupcat1(m_feature), ret[0])
ret[1] = self.gate2(self.mupcat2(m_feature), ret[1])
ret[2] = self.gate3(self.mupcat3(m_feature), ret[2])
|
- EAB 模块处理
ret 列表中的前三个特征图。
- 通过
self.mattn 进行注意力机制处理,得到注意力特征图 m1, m2, m3。
- 将
m1 和 m2 拼接,并通过 mdcat1 模块处理。
- 将处理后的特征图与
m3 拼接,并通过 mdcat2 模块处理,得到融合后的特征图 m_feature。
- 使用转置卷积(
mupcat1, mupcat2, mupcat3)对融合后的特征图进行上采样。
- 使用门控机制(
gate1, gate2, gate3)对上采样后的特征图与原始特征图进行融合,更新 ret 列表中的特征图。
最后两层的处理
最后两层的特征图同样经过 MBTFE 模块处理,但不经过 EAB 模块的特征融合和上采样处理。
关键点总结
MBTFE 模块的输出:
- 每个阶段的卷积块输出特征图后,输入到对应的 MBTFE 模块。
- MBTFE 模块的输出特征图存储在
ret 列表中,并在 forward 方法后续处理中使用。
EAB 模块的输出:
- EAB 模块处理
ret 列表中的前三个特征图,进行注意力机制、特征融合和上采样。
- EAB 模块更新后的特征图存储在
ret 列表中,并用于网络的进一步处理。
数据流向下一层编码器:
- 每个阶段的卷积块经过 MBTFE 模块处理后,输出特征图存储在
ret 列表中。
- EAB 模块在前三层特征图上进行特征融合和上采样,更新
ret 列表中的特征图。
ret 列表中的特征图用于下一层编码器的进一步处理。
通过这种方式,MBTFE 和 EAB 模块协同工作,提升特征提取和融合的能力,确保特征图在每一层都能得到充分的处理和优化。