1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
#######################################################################
Please cite the following paper when using nnU-Net:
Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J., & Maier-Hein, K. H. (2021). nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2), 203-211.
#######################################################################
This is the configuration used by this training:
Configuration name: 3d_fullres
{'data_identifier': 'nnUNetPlans_3d_fullres', 'preprocessor_name': 'DefaultPreprocessor', 'batch_size': 2, 'patch_size': [128, 128, 128], 'median_image_size_in_voxels': [139.0, 169.0, 138.0], 'spacing': [1.0, 1.0, 1.0], 'normalization_schemes': ['ZScoreNormalization', 'ZScoreNormalization', 'ZScoreNormalization', 'ZScoreNormalization'], 'use_mask_for_norm': [True, True, True, True], 'resampling_fn_data': 'resample_data_or_seg_to_shape', 'resampling_fn_seg': 'resample_data_or_seg_to_shape', 'resampling_fn_data_kwargs': {'is_seg': False, 'order': 3, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_seg_kwargs': {'is_seg': True, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_probabilities': 'resample_data_or_seg_to_shape', 'resampling_fn_probabilities_kwargs': {'is_seg': False, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'architecture': {'network_class_name': 'dynamic_network_architectures.architectures.saunet.SAPlainConvUNet', 'arch_kwargs': {'n_stages': 6, 'features_per_stage': [32, 64, 128, 256, 320, 320], 'conv_op': 'torch.nn.modules.conv.Conv3d', 'kernel_sizes': [[3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3]], 'strides': [[1, 1, 1], [2, 2, 2], [2, 2, 2], [2, 2, 2], [2, 2, 2], [2, 2, 2]], 'n_conv_per_stage': [2, 2, 2, 2, 2, 2], 'n_conv_per_stage_decoder': [2, 2, 2, 2, 2], 'conv_bias': True, 'norm_op': 'torch.nn.modules.instancenorm.InstanceNorm3d', 'norm_op_kwargs': {'eps': 1e-05, 'affine': True}, 'dropout_op': None, 'dropout_op_kwargs': None, 'nonlin': 'torch.nn.LeakyReLU', 'nonlin_kwargs': {'inplace': True}, 'deep_supervision': True}, '_kw_requires_import': ['conv_op', 'norm_op', 'dropout_op', 'nonlin']}, 'batch_dice': False}
These are the global plan.json settings:
{'dataset_name': 'Dataset043_BraTS2019_sa', 'plans_name': 'nnUNetPlans', 'original_median_spacing_after_transp': [1.0, 1.0, 1.0], 'original_median_shape_after_transp': [139, 169, 138], 'image_reader_writer': 'SimpleITKIO', 'transpose_forward': [0, 1, 2], 'transpose_backward': [0, 1, 2], 'experiment_planner_used': 'ExperimentPlanner', 'label_manager': 'LabelManager', 'foreground_intensity_properties_per_channel': {'0': {'max': 21113.0, 'mean': 542.999755859375, 'median': 343.0, 'min': 0.0, 'percentile_00_5': 36.0, 'percentile_99_5': 8810.0, 'std': 929.7076416015625}, '1': {'max': 18011.0, 'mean': 637.3016967773438, 'median': 398.0, 'min': 0.0, 'percentile_00_5': 35.0, 'percentile_99_5': 8077.0, 'std': 934.3526611328125}, '2': {'max': 31404.0, 'mean': 929.93505859375, 'median': 629.0, 'min': 0.0, 'percentile_00_5': 94.0, 'percentile_99_5': 16792.0, 'std': 1901.22119140625}, '3': {'max': 29422.0, 'mean': 655.0728149414062, 'median': 409.0, 'min': 0.0, 'percentile_00_5': 65.0, 'percentile_99_5': 16095.0, 'std': 1809.3948974609375}}}
2024-06-28 20:55:38.787769: unpacking dataset...
2024-06-28 20:55:41.889807: unpacking done...
2024-06-28 20:55:41.891027: do_dummy_2d_data_aug: False
2024-06-28 20:55:41.892254: Using splits from existing split file: /home/wzh-dl/nnunet/nnUNet_preprocessed/Dataset043_BraTS2019_sa/splits_final.json
2024-06-28 20:55:41.892995: The split file contains 5 splits.
2024-06-28 20:55:41.893032: Desired fold for training: 0
2024-06-28 20:55:41.893061: This split has 268 training and 67 validation cases.
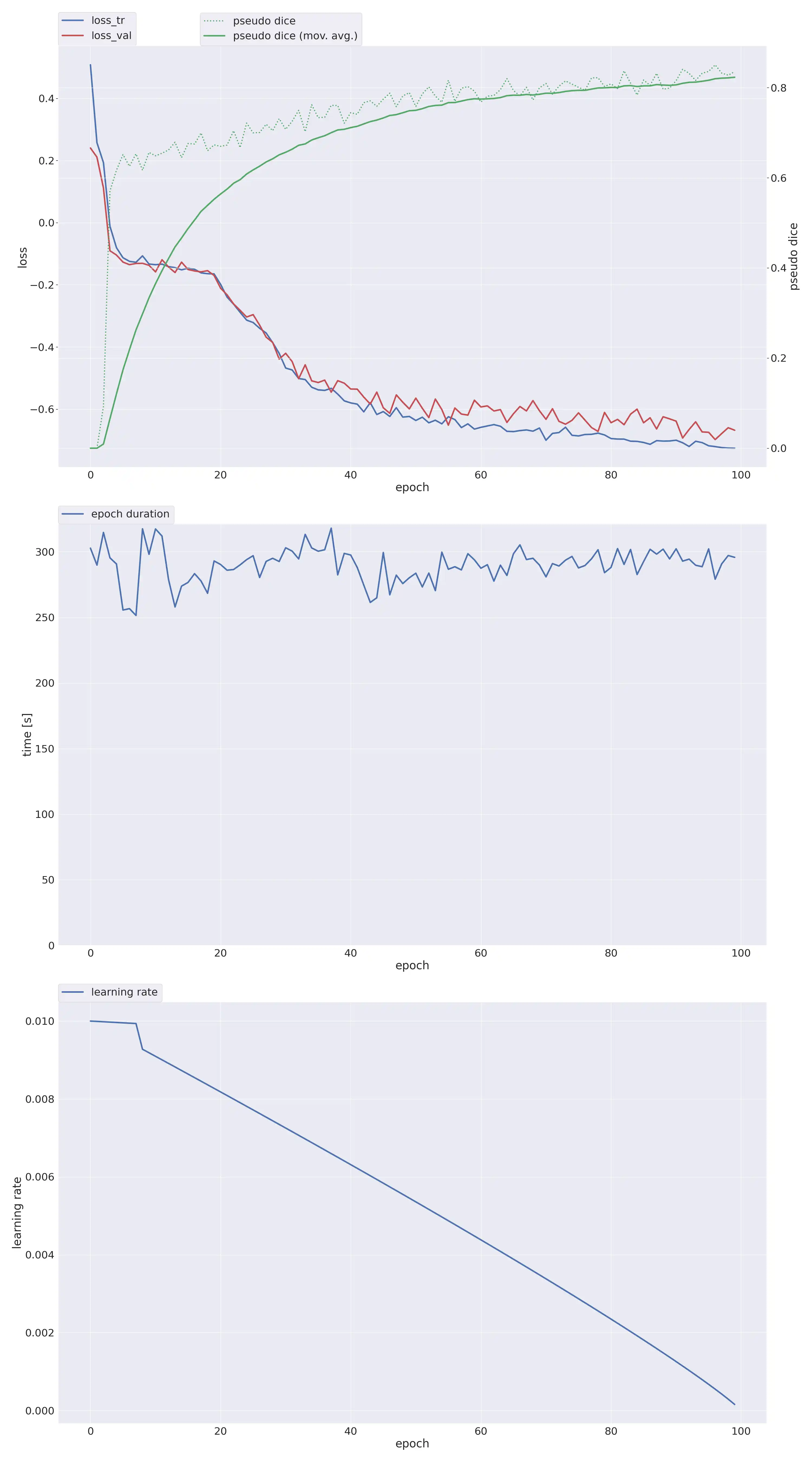
2024-06-28 20:55:41.902031: Unable to plot network architecture:
2024-06-28 20:55:41.902077: No module named 'hiddenlayer'
2024-06-28 20:55:41.912451:
2024-06-28 20:55:41.912497: Epoch 0
2024-06-28 20:55:41.912628: Current learning rate: 0.01
2024-06-28 21:00:15.003617: train_loss 0.3861
2024-06-28 21:00:15.006468: val_loss 0.319
2024-06-28 21:00:15.006593: Pseudo dice [np.float32(0.0), np.float32(0.0), np.float32(0.0)]
2024-06-28 21:00:15.007578: Epoch time: 273.09 s
2024-06-28 21:00:15.007675: Yayy! New best EMA pseudo Dice: 0.0
2024-06-28 21:00:19.410886:
2024-06-28 21:00:19.411277: Epoch 1
2024-06-28 21:00:19.411479: Current learning rate: 0.00991
2024-06-28 21:04:29.235484: train_loss 0.2494
2024-06-28 21:04:29.241981: val_loss 0.2322
2024-06-28 21:04:29.242288: Pseudo dice [np.float32(0.0), np.float32(0.0), np.float32(0.0)]
2024-06-28 21:04:29.243144: Epoch time: 249.83 s
2024-06-28 21:04:32.809436:
2024-06-28 21:04:32.809648: Epoch 2
2024-06-28 21:04:32.809788: Current learning rate: 0.00982
|