验证
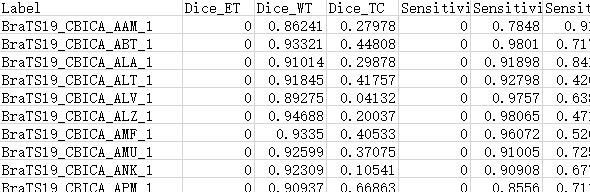
昨天验证的有问题,ET没有数据。

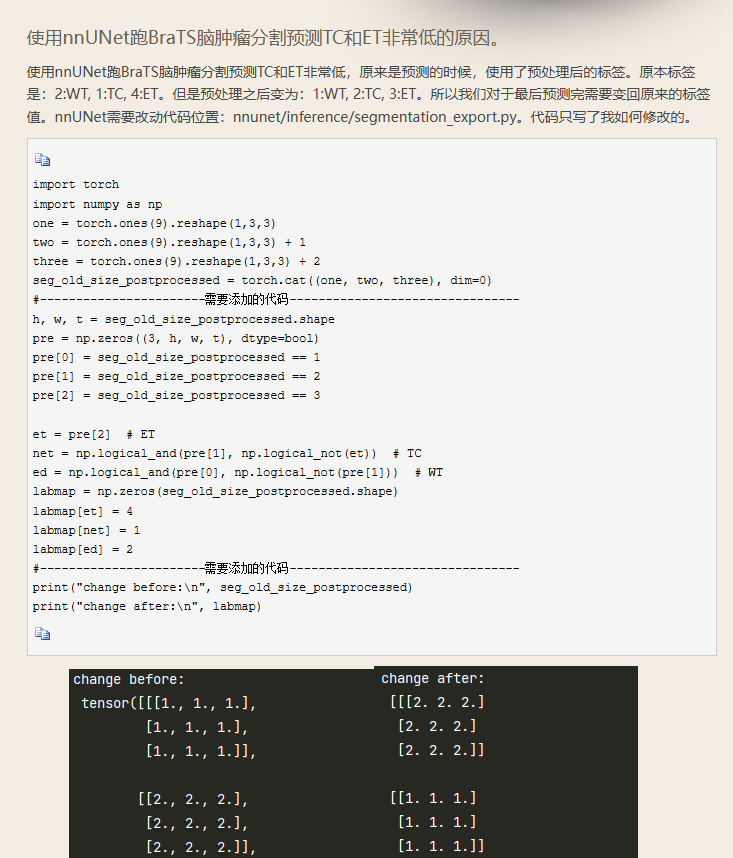
然后在网上看到一篇文章,说是nnunet在预处理的时候会把分割的标签改成0-3,但是数据集原始的标签序号不是0-3,所以就会出现问题。
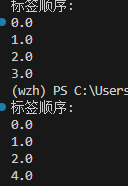
于是就跟AI友好交流写了个代码查看标签的原始信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
| import nibabel as nib
import numpy as np
def check_labels(input_path):
img = nib.load(input_path)
data = img.get_fdata()
unique_labels = np.unique(data)
return unique_labels
# 使用范例
input_file = r"D:\深度学习\结果\√0.9046PretrainedSTUNetTrainer_base__nnUNetPlans__3d_fullres\infer\remapped\BraTS19_CBICA_AAM_1.nii.gz"
labels = check_labels(input_file)
print(f'Unique labels in {input_file}: {labels}')
|
查看了原始数据集中训练集和输出的验证集的分割文件做一下对比,确实是有问题:
看刚才那篇文章上说,需要更改nnunet的代码。但是根据他这篇文章写作的时间还有代码结构,应该是nnunetv1时代的产物,我现在一直都是用的V2。所以这个代码用不了。看了半天也没在v2的代码里找到类似的代码。
于是灵机一动,不如直接从生成的文件下手,直接更改标签的编号算了。于是又跟AI交流了一下,写出了如下的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import nibabel as nib
import numpy as np
import os
def remap_labels(input_path, output_path):
# 加载标签文件
img = nib.load(input_path)
data = img.get_fdata()
# 创建一个空的数组来存储新的标签
new_data = np.zeros_like(data)
# 转换标签
new_data[data == 0] = 0 # Background
new_data[data == 1] = 1 # WT remains the same
new_data[data == 2] = 2 # TC remains the same
new_data[data == 3] = 4 # ET: 3 -> 4
# 确保标签值为整数类型
new_data = new_data.astype(np.int16)
# 保存新的标签文件
new_img = nib.Nifti1Image(new_data, img.affine, img.header)
nib.save(new_img, output_path)
def batch_remap_labels(input_folder, output_folder):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for filename in os.listdir(input_folder):
if filename.endswith('.nii.gz'):
input_path = os.path.join(input_folder, filename)
output_path = os.path.join(output_folder, filename)
remap_labels(input_path, output_path)
print(f'Processed {filename}')
# 使用范例
input_folder = 'D:\深度学习\结果\√0.90641nnUNetTrainer__nnUNetPlans__EAB__3d_fullres_100EPOCH\post'
output_folder = os.path.join(input_folder, 'remapped')
batch_remap_labels(input_folder, output_folder)
|
把之前所有的数据的标签全部更改了下。中间还出现了小插曲,更改的标签编号不是整数,难绷。
然后重新提交上去进行验证:
最终得到了如下的结论,其他两个任务都一样,就第一个ET的数据也出来了,这个TC感觉低得有点不合理,不知道是不是训练轮次太少的原因。不过看曲线应该也收敛了,那就不知道了。原版nnunet都这样,可能是正常的吧。如下:(没写完,刚写的没保存,焯)
| Model |
Dice_ET |
Dice_WT |
Dice_TC |
Sensitivity_ET |
Sensitivity_WT |
Sensitivity_TC |
Specificity_ET |
Specificity_WT |
Specificity_TC |
Hausdorff95_ET |
Hausdorff95_WT |
Hausdorff95_TC |
| eab-nnunet |
0.74459 |
0.90641 |
0.39029 |
0.78645 |
0.90544 |
0.62394 |
0.99839 |
0.99518 |
0.96524 |
3.54292 |
4.54008 |
16.91987 |
| plain-nnunet |
0.73716 |
0.90297 |
0.38221 |
0.76966 |
0.9024 |
0.60403 |
0.99057 |
0.98712 |
0.95677 |
33.44588 |
7.47936 |
19.83174 |
| stunet-pretr-base |
0.73427 |
0.90460 |
0.38761 |
0.78325 |
0.90565 |
0.61204 |
0.99857 |
0.99539 |
0.96549 |
3.47016 |
4.56391 |
16.51672 |
| stunet-small |
0.72337 |
0.90397 |
0.38184 |
0.77114 |
0.90648 |
0.60293 |
0.99855 |
0.99499 |
0.96494 |
4.1006 |
4.85547 |
16.80102 |